整理我与 AI 的对话和思考,记录关于大模型、技术变化与智能时代的持续观察与实践。文末用日常语言做整体理解。
这篇文章讲什么
Transformer 是 2017 年 Google 提出的一种神经网络架构(论文标题:「Attention Is All You Need」)。它是当今几乎所有主流大模型的基础——ChatGPT、Claude、Gemini、Llama 都建立在 Transformer 之上。
在 Transformer 出现之前,语言模型主流路线是「一个词一个词顺序处理」(RNN),效率低、记忆短。Transformer 的核心创新叫做 Attention(注意力机制):让模型在处理任何一个词时,同时参考文本里的所有其他词,从而理解长距离的语义关系。
这个架构上的突破,加上算力和数据的规模化,直接催生了 ChatGPT 这一代 AI 的爆发。理解 Transformer,就理解了为什么现在的 AI 这么强。本篇用类比(维度变化)让这个概念变得直观。
Transformer 之前,语言模型是怎么做的?
主流方案是 RNN(循环神经网络):像读书一样,一个词一个词顺序处理。
问题:读到后面,早期的信息已经「传递稀释」得差不多了。一篇文章第一段的关键信息,到第十段时模型已经「快忘了」。
更深的问题:顺序处理意味着无法并行——每个词必须等前一个词处理完,GPU 大量算力被白白浪费。
Transformer 核心是什么?为什么突破了?
核心创新:Attention(注意力)机制——让每个词同时看到所有词。
不再一步步传递信息,而是:对当前这个词,直接计算它和序列里所有词的相关性,然后按相关性加权提取信息。
效果:
- 长距离依赖大幅缓解:文章开头和结尾的词可以直接关联,距离不再是主要障碍
- 训练时可完全并行:所有词的 Attention 可同时计算,GPU 利用率大幅提升(推理生成时仍需逐 token,靠 KV cache 复用历史计算)
- Scale 有效:模型越大越聪明(RNN 时代收益递减得很快,远不如 Transformer 这样持续受益)
这个框架改变是质变,不只是量变——它解放了深度学习本来就有的能力,让「越大越强」成为可能。

Attention 从一维变成多维了吗?
是个很好的类比。
RNN:一维时间轴,信息按顺序流动。 Transformer:每个词和所有词构成关系矩阵(二维),直接查任意位置。
更进一步——多头 Attention(Multi-Head Attention)是多个矩阵并行:
Head 1 偏向语法关系(主谓宾)
Head 2 偏向语义关系(同义、反义)
Head 3 偏向位置关系(远近)
...
多个视角同时计算,最后合并
注:上述分工只是直觉示意。实际研究(如 BERT 可解释性分析)表明,部分 Head 确实偏好特定模式(指代、句法依存等),但多数 Head 功能是混合的,不存在严格「一个 Head 一个职责」的对应。重要的是「多个 Head 并行带来多视角」这个结构本身。
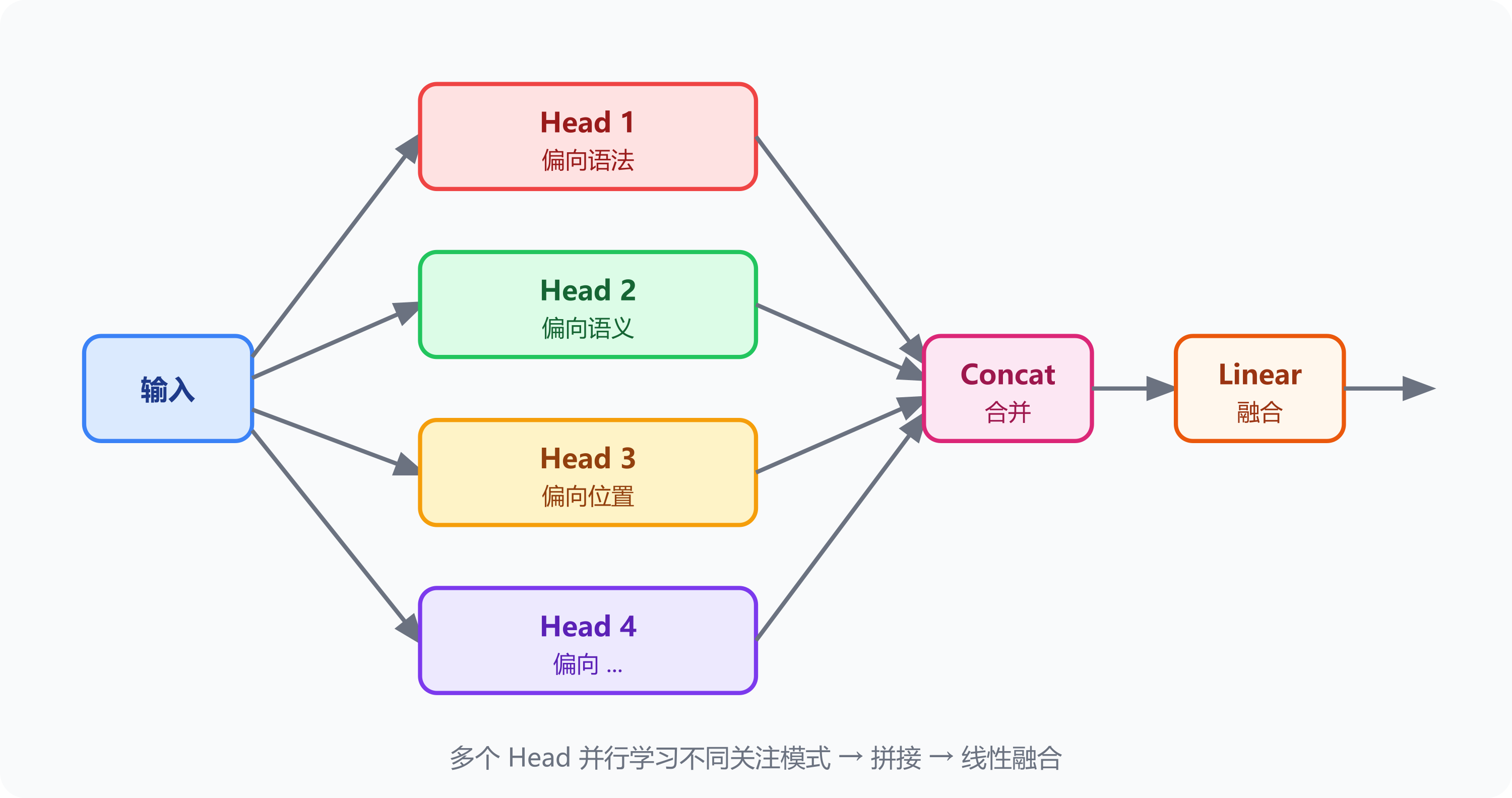
从一维线性流动 → 多维关系图。「体」的比喻也成立:信息有长度(序列)、宽度(词的维度)、深度(多个 Head),是三维的。
注意力相关性是怎么计算的?Q、K、V 是什么?
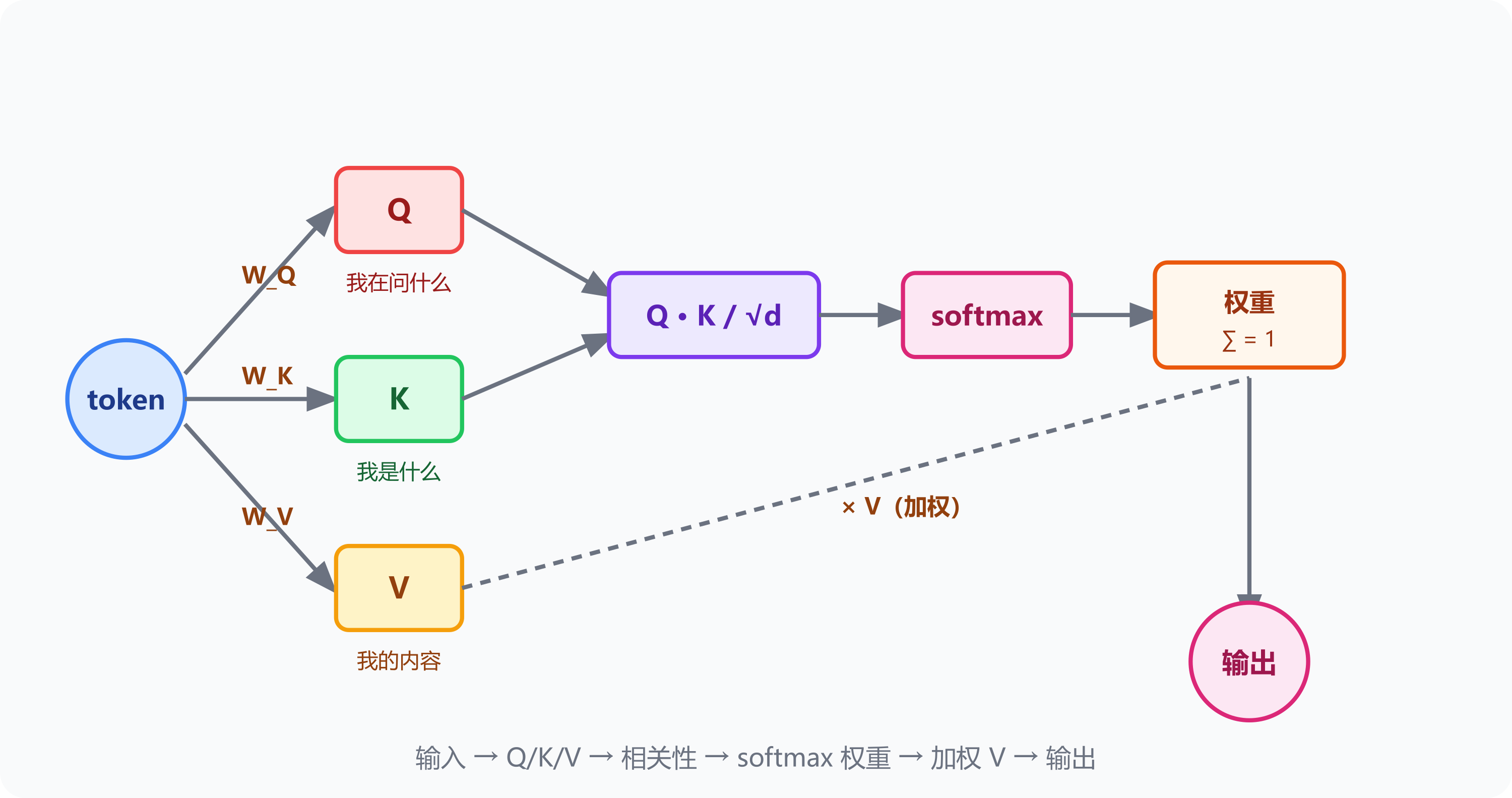
每个词被映射成三个向量:
- Q(Query,我在问什么):「我在找什么信息」
- K(Key,我是什么):「我能提供什么信息」
- V(Value,我的内容):「我实际的信息内容」
计算流程:
相关性分数 = Q · K(点积)/ √维度
→ softmax 归一化成权重(加起来 = 1)
→ 输出 = 所有词的 V × 对应权重 的加权和
点积为什么能表示相关性:两个向量方向越接近,点积越大 → 相关性越高。就像两个人的喜好方向越接近,他们越「对味」。
为什么除以 √维度:防止点积值太大,导致 softmax 输出分布过于极端(所有权重集中在一个词上),影响梯度流动。
Q/K/V 的变换矩阵:都是训练出来的,不是人工设计的。模型学会了「什么样的问题-键匹配能帮助预测准确」。
权重可以理解为「专业性」吗?
方向对,作为直觉类比可以。(严格说专业性是稳定属性,attention 权重是动态的,每次推理重算。)
Attention 权重 = 当前 token 对其他 token 的「注意程度」。
类比:
- 有人问「如何优化数据库查询」
- 技术背景的人 attention 权重高集中在「索引、查询计划」
- 非技术人注意力可能更多在「数据库是什么」
不同的 Attention Head 会学到不同的关注模式(并非严格分工,前文已说明)。
两种权重区分:
- 训练权重(参数):Q/K/V 的变换矩阵,训练后固定
- Attention 权重(动态):每次推理时根据输入实时计算,不存储
Attention 和人类记忆遗忘有关系吗?
方向对,但机制不一样。
人类记忆:时间维度遗忘,复习强化,长时间不用会忘。 Attention:空间维度权重,不是时间遗忘。所有 token 同时在 context 里,没有遗忘——只是有的词被赋予高权重(重要),有的低权重(不相关)。
真正像人类遗忘的是:context 长度限制。超出 200K/1M 的内容会被截断,确实「忘了」。这更像人的工作记忆(短期记忆容量有限),而不是 Attention 机制本身。
深度学习「变深」是力大砖飞吗?
**基本是,**深度(层数多)确实能学到更抽象的特征。粗略趋势:
- 浅层:偏向局部、表层模式(词形、相邻搭配)
- 中层:偏向组合特征(短语、句法关系)
- 深层:偏向高层语义(概念、指代、推理关系)
注:这是平均趋势,不是严格对应。可解释性研究表明各层功能有重叠,且不同模型差异较大。
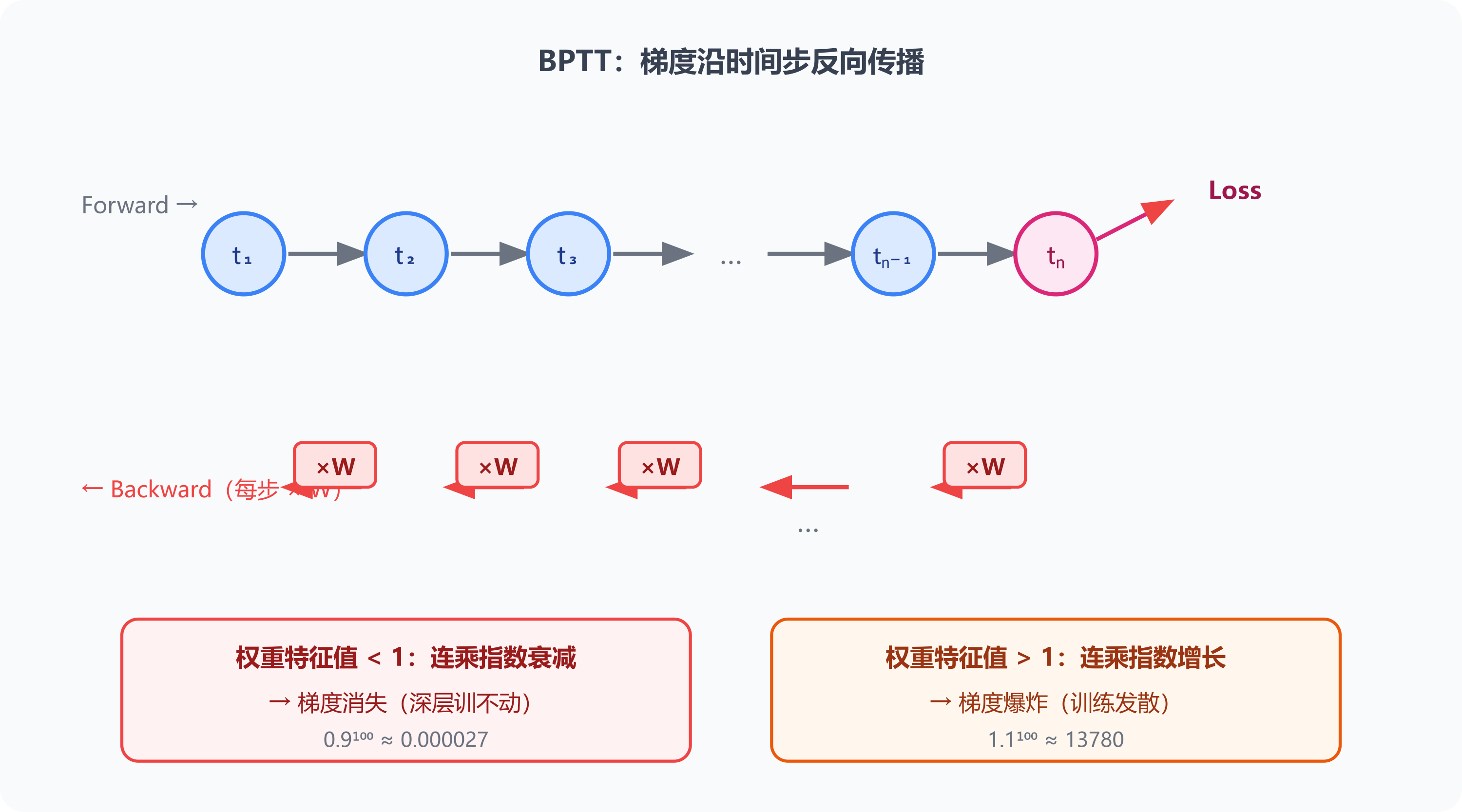
RNN 时代变深有问题:梯度在沿时间步反向传播时容易指数衰减或爆炸(梯度消失/爆炸),深层难以稳定训练,「能力有但施展不开」。
Transformer 解决了这个:残差连接让梯度跨层稳定流动;attention 则让任意两个 token 直接关联,不再依赖逐步传递。有了这个基础,「变深 + 变宽 + 更多数据」才真正有效——能力空间一直在,Transformer 打开了施展的通道。
梯度是什么?
训练神经网络时,每个权重应该「往哪个方向调、调多少」,这个「调整指令」就是梯度。直觉理解:把训练目标想象成一座山的高度(loss 越低越好),梯度告诉你站在当前位置时,往哪边走下山最快、坡有多陡。
预测错了 → 算出 loss
对每个权重问:「这个权重微调一点,loss 会变多少?」
答案 = 梯度
按梯度反方向更新权重 → 一步步下山
梯度消失就是这个指令在反向传播时被一层一层稀释,传到前面的层时已经接近 0——模型「知道错了,但不知道怎么调」,深层就训不动了。梯度爆炸则相反,指令越传越大,权重剧烈震荡,训练直接发散。
沿时间步反向传播是什么?为什么要这样?
一句话:梯度沿序列从最后一步往前一层层传回去。英文叫 BPTT(Backpropagation Through Time)。
为什么必须从后往前传?
Loss 只能在最后一步算出来(预测 vs 实际)。但要调的是中间所有权重——怎么知道哪个权重该担多少责?数学上靠链式法则:从最后一步开始反推,每一层的梯度依赖后一层已经算好的中间结果。
反过来从前往后算行不行?理论上可以,但每个权重都要重跑一遍 forward,计算量平方级膨胀。反向一次遍历,所有权重的梯度同时算完——这就是为什么必须从后往前。
类比:项目失败追责。从结果往回查——「这一步谁拍板?上一步谁提供的输入?」一路追到源头,比「列出所有可能原因再正向验证一遍」高效得多。
RNN 的「时间步」从哪来?
RNN 处理序列时,把每个 token 当作一个时间步(t=1, t=2, ..., t=n),每一步共享同一组权重。展开来看,序列越长,「层」越多。所以梯度要从 t=n 沿时间链一路传回 t=1。这就是「沿时间步反向传播」。
算法亲缘——动态规划,不是回溯
直觉上「从结果回溯到原因」会让人想到回溯算法,但严格来说不是。回溯是「试错 + 撤销」(像解数独:试一条路,错了就退回来换一条),核心是搜索。
反向传播更接近动态规划:把大问题拆成子问题,复用已经算过的中间结果,自顶向下分解、自底向上汇总。类似 Fibonacci 用 memoization 避免重复计算——每个节点的梯度只算一次,存起来给前面的节点用。
| 算法 | 核心动作 | 与反向传播 |
|---|---|---|
| 回溯 | 试错 + 撤销 | ❌ 方向像,机制不同 |
| 动态规划 | 子问题复用 | ✅ 本质就是 |
| 关键路径 | DAG 正反两次遍历 | ✅ 结构同构 |
一句话:反向传播 = 计算图(DAG)上的 DP,与数据结构课的「关键路径」同构。
为什么 BPTT 在 RNN 上特别容易爆雷?
链上每一步都要乘一次权重矩阵,n 步就是 n 次连续矩阵乘法:
- 权重特征值 < 1 → 连乘指数衰减 → 梯度消失(前面的层收不到有效信号)
- 权重特征值 > 1 → 连乘指数增长 → 梯度爆炸(更新幅度失控)
序列越长越严重。LSTM/GRU 用门控(gating)部分缓解,但没根治。Transformer 干脆抛弃时间链——任意两个 token 通过 attention 直接相连,梯度路径只过常数层数,问题大幅减轻。这也是「Transformer 解放了变深」的真正原因。
这就像一个人接一个人传话再回话,极易出问题。但两个人之间对话,效果就好很多。
所有大模型都用 Transformer 吗?它们在哪里分叉?
主流是,但开始有替代方案:
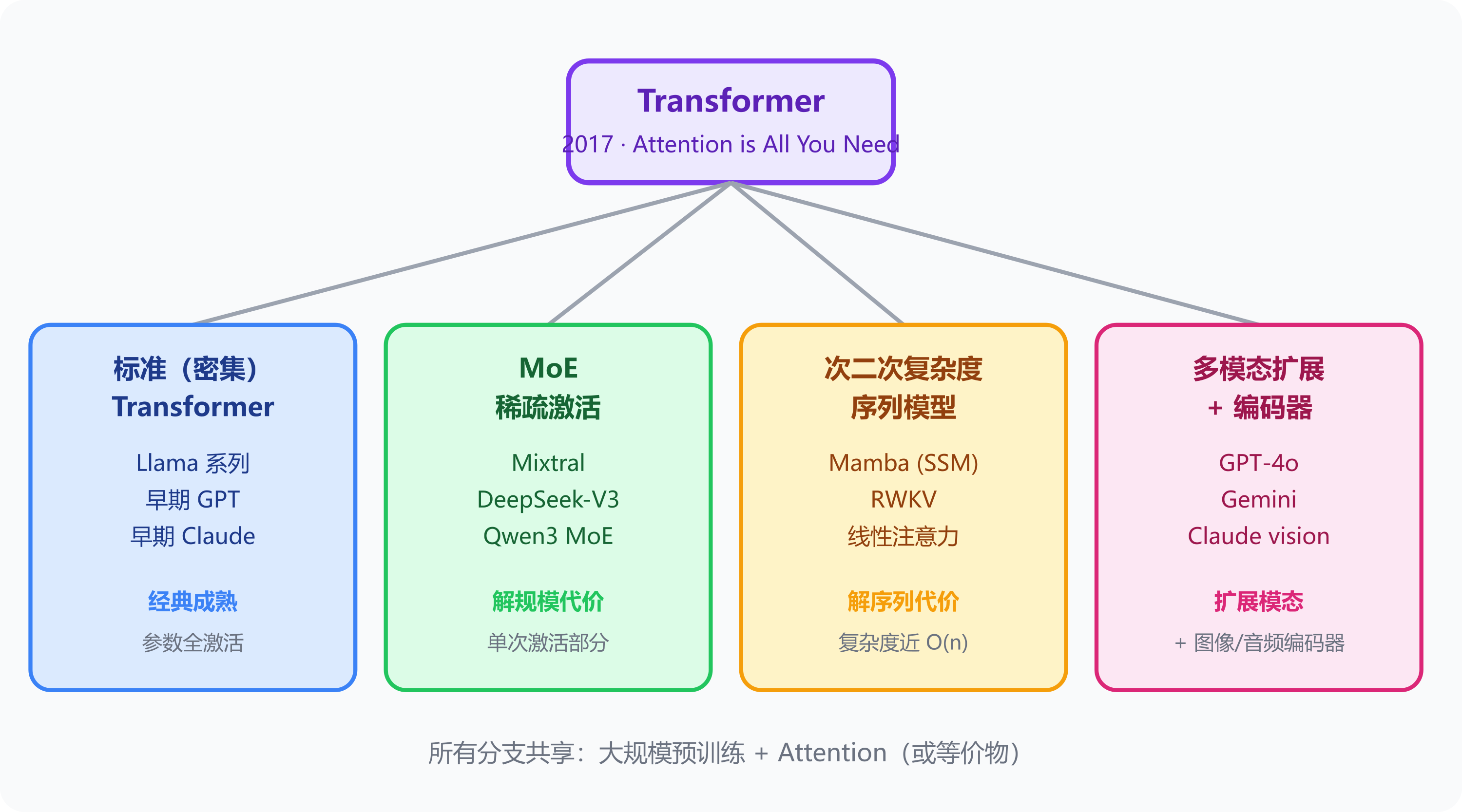
| 方向 | 代表 | 核心改变 |
|---|---|---|
| 标准(密集)Transformer | Llama 系列、早期 GPT、早期 Claude | 经典,成熟 |
| Mixture of Experts | Mixtral、Qwen3 MoE | 稀疏激活,省计算 |
| 次二次复杂度序列模型 | Mamba(SSM)、RWKV(线性注意力 RNN) | 替代 Attention,复杂度近 O(n),超长序列更高效 |
| 多模态扩展 | GPT-4o、Gemini | Transformer + 图像/音频编码器 |
注:GPT-4、Claude、Gemini 等闭源模型的具体架构未公开,业内普遍推测部分已采用 MoE,但不确定。
主要分叉点有两个:
- 序列长度的代价:Attention 复杂度是 O(n²)(序列翻倍,计算量翻 4 倍),超长序列非常贵。Mamba、各种线性注意力是直接奔着这个去的。
- 模型规模的代价:模型继续变大时如何让计算成本可控。MoE 通过「稀疏激活」(参数很多但单次推理只激活一部分专家)解决这个,并不是冲着 O(n²) 去的。
哲学核心(大规模预训练 + Attention 或其等价物)基本一致,工程细节分叉。
用「把文字变成向量再做计算」还有哪些应用?
「把任意信息压缩到统一的向量空间,用距离衡量关系」是整个 AI 生态的底层思想。
| 领域 | 输入 | 向量用途 |
|---|---|---|
| 跨语言搜索(CLIP) | 文字/图片 | 同一空间匹配,跨模态 |
| 人脸识别 | 人脸图片 | 向量距离判断是否同一人 |
| 推荐系统 | 用户行为、商品 | 用户向量 × 商品向量 = 相关性 |
| 代码搜索 | 自然语言 | 语义搜代码,不靠关键词 |
| 音频识别 | 音频频谱 | 向量化后解码成文字 |
| 药物发现 | 化学结构 | 向量相似 = 功能相似 |
有一种直觉上的理解方式:「转了一下方向,以相同角度去看所有东西,从而找出它们之间的关系」(线性代数)。这个直觉是准确的。严格来说,embedding 是「弯曲+旋转+压缩」的组合变换(涉及非线性),但目标一样:让语义相近的东西在新的坐标系里靠近,不相关的分开。
语音模型参数越多,识别精度越高吗?
**对,**参数多的语音模型能做到的是:
- 识别更多口音、方言
- 在噪音环境下仍能准确识别
- 理解模糊、快速的发音
类比:见过更多种说话方式,猜测(模式匹配)能力更强。
大模型之前的语音方案(HMM+GMM 等传统统计方法,主导期约为 1980s–2010s 早期):手工提取声学特征,规则拼接,需要大量标注数据,换个语言/口音就得重头来。Whisper(OpenAI,2022,基于 Transformer,支持约 99 种语言转录)一个模型就能处理多语言、噪音、口音、快语速——这背后是「参数多 + 数据大(68 万小时弱监督音频)+ 好架构」共同作用的结果。
注:Whisper 的强能力主要来自大规模弱监督训练,严格来说和「涌现」不完全等价;但「规模化解决了过去靠规则解决不了的问题」这个观察是成立的。
核心要点
- RNN 的问题:顺序处理,早期信息被逐步稀释;无法并行,GPU 浪费;梯度消失,变深无效
- Transformer 的突破:Attention 让每个词直接看所有词,复杂度 O(n²),但大幅缓解了长距离依赖问题,并让训练可完全并行
- Q / K / V:Query(我在找什么)× Key(你是什么)= 相关性分数;相关性加权 × Value(你的内容)= 输出
- 点积为什么能表示相关性:两个向量方向越接近,点积越大;除以 √维度 防止 softmax 过度极化
- 多头 Attention:多个 Head 并行,倾向不同关注模式(粗略说语法 / 语义 / 位置,但实际功能多有重叠),最后合并
- 两种权重区分:训练权重(Q/K/V 变换矩阵,训练后固定)vs Attention 权重(每次推理动态计算,不存储)
- Context 截断 ≠ 遗忘:Attention 里所有 token 同时存在,无时间衰减;真正的「遗忘」是超出 context 长度被截断
- 梯度消失的解决:残差连接让梯度稳定流过深层;Transformer 打通了「变深 + 变宽 + 更多数据」的通道
- Scale 有效:RNN 时代变大不一定变强;Transformer 解放了这个空间,「越大越聪明」成为规律
Transformer 的价值不只是解决了一个技术问题,它证明了「让信息流动方式变对,能力就会涌现」。这个思路影响了之后几乎所有 AI 架构的设计方向。
日常总结
注意力是更接近「理解」的方式
人读一句话,从来不是一个字一个字往下顺。读到「他把钥匙落在车里了」时,「他」「钥匙」「车」三者的关系是同时建立的,不需要先记住前半句再去对后半句。注意力机制做的就是这件事——把人本来就在用的理解方式,写进了模型的架构里。
RNN 像是逼着模型「从头读到尾,边读边忘」,Transformer 则是「全文摊开,谁和谁有关系直接连线」。这不是更聪明的算法,而是更贴近理解本身的结构。所以它在长文本、跨段呼应、隐含逻辑这些任务上突然变强,不是巧合——是终于让模型用对了方法。
多个视角同时看,不是看得更细
多头注意力听起来像是「看得更仔细」,其实是「同时用多种眼光看」。一个头盯语法,一个头盯语义,一个头盯位置远近,最后再合起来。
人也这样。读一首诗,音律、意象、典故是同时感受的,不是先读完一遍抓字面,再读一遍找美感。所谓理解力强,往往不是想得更深,而是同一时刻能从更多角度看同一个东西。多头注意力的设计思路,和这种「多角度并行」的直觉是相通的。
并行能跑才接得住,架构决定能跑多远
Transformer 有一件事经常被忽略:它能让所有词同时计算,不像 RNN 必须排队等。GPU 的本事就是「同时干很多件事」。RNN 时代在语言任务上,再多卡也用得不充分——任务本身串行,算力发挥不出来。Transformer 来了之后,GPU 在 NLP 上的潜力才被真正榨干。所以这一波 AI 爆发,不只是「有了更好的模型」,而是「模型终于能配得上手里的算力」。
可以这样想:数据是原料,算力是燃料,架构是发动机。原料再多、燃料再足,发动机结构不对,能跑出来的速度就是有上限的。Transformer 出现之前,「让模型变大」这条路收益递减得很快——变大不一定变强。Transformer 把这条路打通了,「越大越聪明」才从猜想变成规律(也就是后来说的 scaling laws)。
AI 这几年的爆发,不只是「数据多了、算力强了」,而是「正好有一种架构,让前两者的潜力释放出来了」。三件事缺一不可,而架构是最容易被忽略的那一个。
向量化是 AI 的通用语言
把文字、图片、声音、化学结构都压成一串数字,再用距离衡量它们之间的关系——这件事看起来抽象,但是 AI 这一代真正的底层共识。一旦所有东西都进了同一个空间,跨模态搜索、推荐、识别、配对就都变成同一个问题:找距离近的。
这有点像人脑的工作方式。我们记一个人的脸、一段旋律、一种气味,存的也不是原始像素或波形,而是某种「特征」。等下次遇到时,靠相似度去对上号。AI 把这个过程明确化、数字化了。Transformer 强在「在这个空间里建立关系」,而向量化提供了「让所有东西都能进这个空间」的入口。两件事合在一起,才有今天 AI 的通用感。
没有免费午餐
注意力虽好,代价是 O(n²)——序列翻倍,计算翻四倍。所以处理长文档、长视频、整本书时,成本会爆炸式增长。这不是工程问题,是机制本身的边界。
Mamba 想直接换掉 attention,线性 / 滑窗注意力想把 O(n²) 降到接近 O(n);MoE 则从另一个方向——参数继续变大但单次推理只激活一部分。这些尝试都说明:Transformer 不是终点,只是目前性价比最好的方案。理解一项技术,既要看清它解决了什么,也要知道它没解决什么——下一个突破,往往就藏在它的代价里。
感谢阅读。如果觉得不错,随手点赞、在看、关注三连吧~