本文内容较长,分上、中、下三篇发布,此为下篇。
前情提要 · 上篇:神经网络——AI 的底层是怎么运作的? · 中篇:涌现与训练——大模型是怎么学会的?
上篇讲了大模型的底层——神经元极其简单,靠权重和非线性叠出复杂能力,逻辑是学出来的,不是人写的。中篇讲了训练过程——用海量文本反复预测下一个词,梯度调权重,循环几万亿次,模型学会了语言,能力随规模出现质变,这就是涌现。这篇来讲“幻觉——AI 为什么会一本正经地说错?”
幻觉是什么?为什么会发生?
幻觉 = 模型生成了听起来合理但事实错误的内容。
根本原因:模型不是在查数据库,是在预测下一个最可能的 token。
幻觉的产生机制:
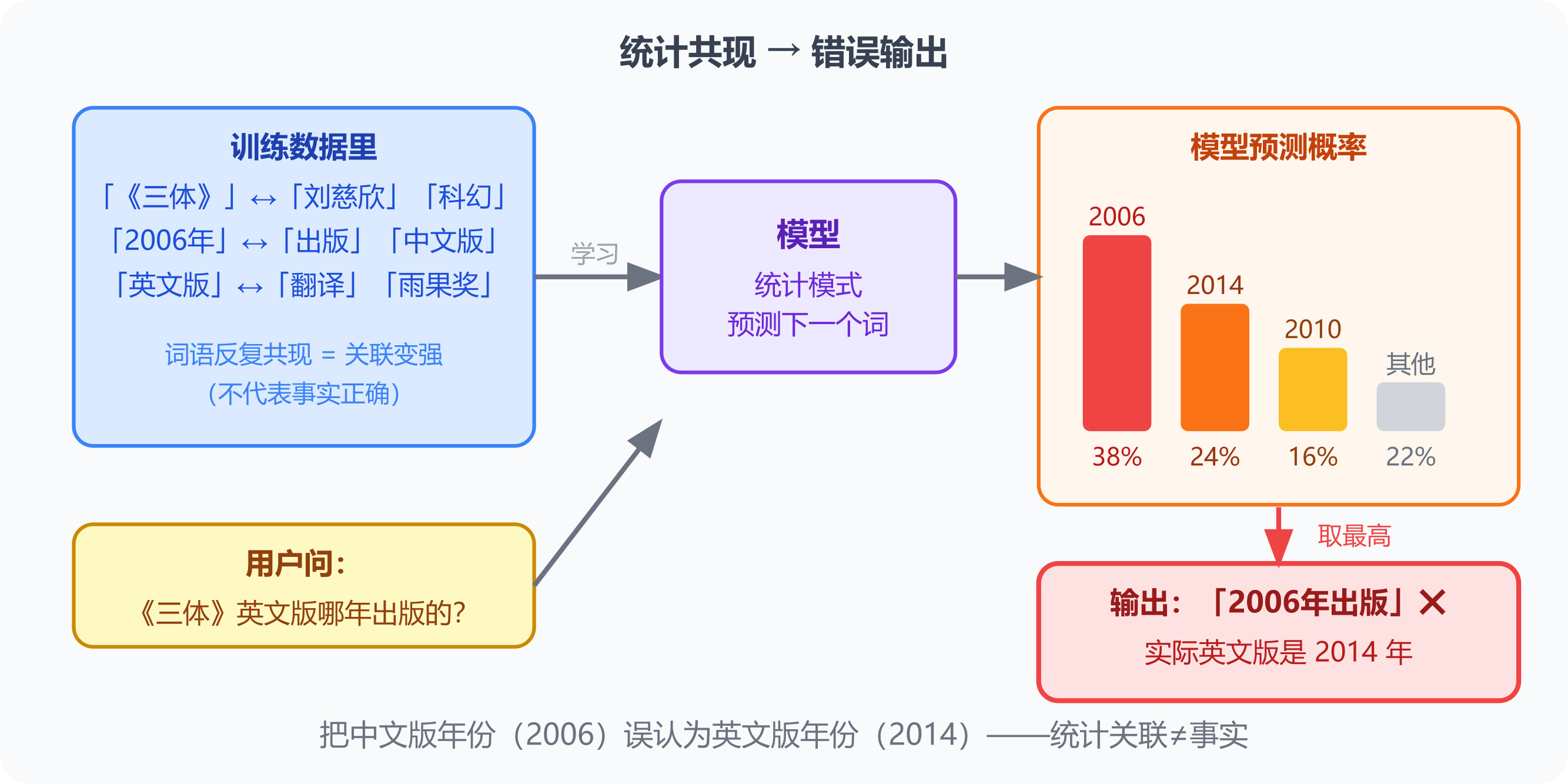
它不是在说谎,也不是查错了数据库——它根本没有查。纯粹是统计模式匹配产生了错误组合。
类比:人类也有「概念混淆」——两个概念经常一起出现,就产生「它们有因果关系」的错觉。幻觉是同一个机制在模型里的体现。
幻觉是能力的代价,不是 bug。想要 100% 确定的答案,用数据库查询,不用生成模型。
好发于:具体数字、版本号、规格、冷门事实。技术规格类问题,永远要验证。
幻觉有没有好的解决方案?
| 方法 | 效果 | 代价 |
|---|---|---|
| RAG(检索增强,给模型实时参考) | 高 | 需要搭检索系统 |
| 提高推理深度(低 / 中 / 高) | 中(更仔细但仍会错) | 贵 |
| 明确要求「不确定就说不知道」 | 中 | 在给 AI 的指令里加上即可 |
| 多次采样取多数 | 中 | 慢且贵 |
| 人工/程序验证 | 最可靠 | 需要额外工作 |
RAG 是什么原理:
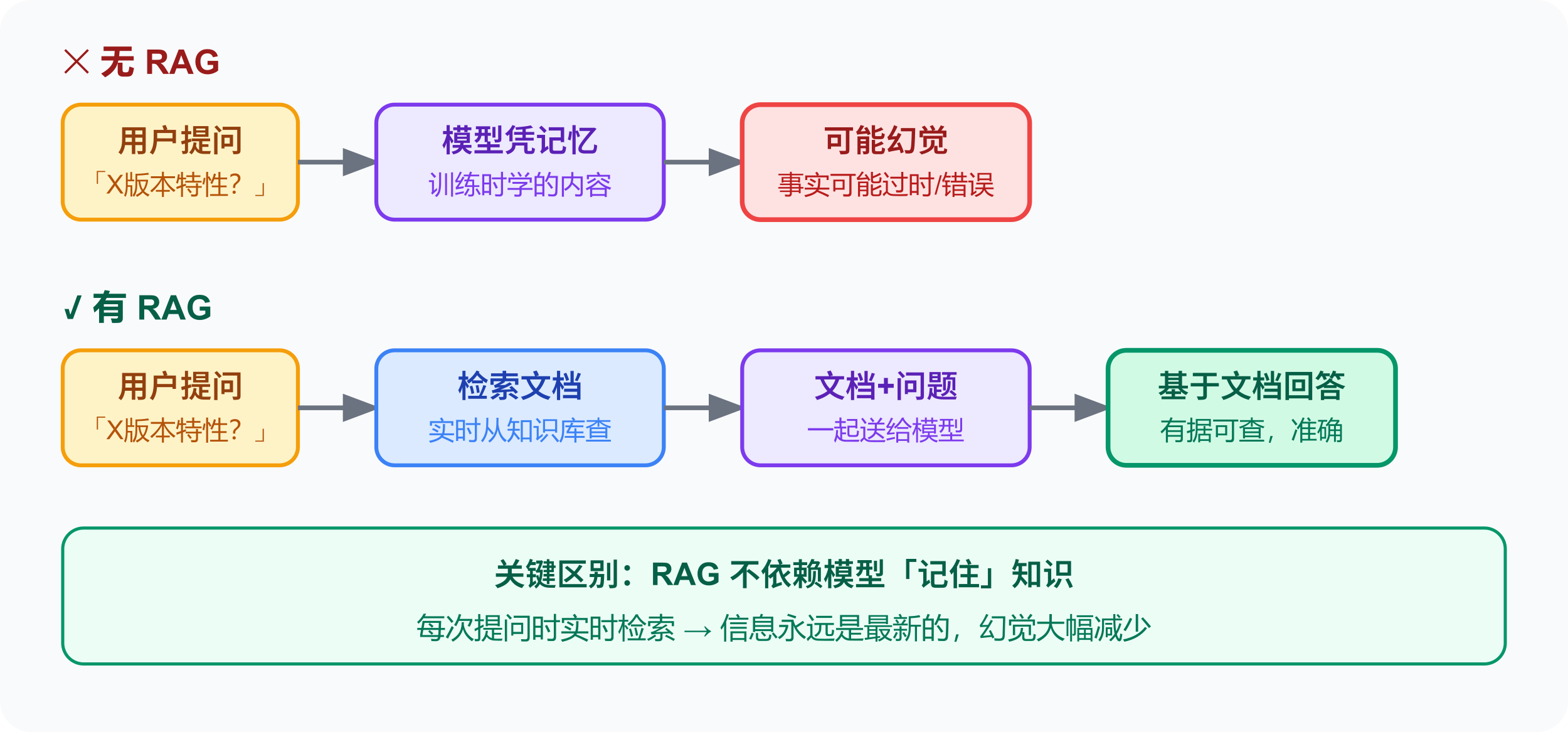
让 AI 主动说不确定,可以在对话开头加一句:「对于具体事实——不确定就明确说『我不确定,建议验证』。」
神经网络、深度学习、大模型——谁是谁的基础?

- 神经网络:基础概念,单层也算
- 深度学习:神经网络变深(很多层),突破了早期瓶颈
- 大模型:深度学习的超规模应用,加了 Transformer 架构
大模型是深度学习的子集,深度学习是神经网络的子集。
本篇小结
幻觉它不是偶发故障,而是「预测下一个词」这个机制的必然产物——能力和风险来自同一个根源。
- 幻觉的根本原因:模型在做统计模式匹配,不是在查数据库。「《三体》英文版出版年份」这类错误来自训练数据里的词语共现,不是在说谎
- 好发场景:具体数字、版本号、规格、冷门事实。这类问题永远要验证
- 最有效的应对:RAG 给模型实时参考资料;或在提示词里明确要求「不确定就说不确定」
三篇串起来是一条完整的认知链:神经元 → 训练 → 幻觉。知道它是怎么建起来的,才知道它会在哪里出问题,才能更有效地使用它。
延伸思考
概率
大模型真正不同的地方,是它不是按固定规则返回确定结果,而是基于概率分布生成答案。传统系统追求稳定:相同输入,基本得到相同输出;但大模型的价值,恰恰来自这种受控的不确定性。它能在概率空间里组合、变化、探索,因此才有创造性和适应性。
这有点像生物进化:如果基因完全不变,系统一旦有致命缺陷,就没有容错空间;而变化带来了新的可能性。对大模型来说,概率不是缺陷,而是能力的来源。它真正的分水岭,不是"更大的数据库",而是从确定性规则走向概率化生成。
大模型约等于人
训练大模型的过程,可以类比人的成长过程。模型架构,就像人先天的神经结构和基础能力;而输入的数据,则像人后天所处的环境、教育和经历。即使先天条件相似,只要接受的信息不同,内部形成的反应方式和判断倾向(权重)也会不同。
所以看大模型时,可以尽量从"人的成长"这个角度去理解:它不是简单地存储知识,而是在特定架构下,被大量数据塑造出一套反应模式和认知方式。大模型的训练,本质上就是一个系统被环境长期塑造的过程。