本文内容较长,分上、中、下三篇发布,此为中篇。
前情提要 · 上篇:神经网络——AI 的底层是怎么运作的?
大模型的底层是神经网络——神经元极其简单,靠权重和非线性叠出复杂能力,逻辑是学出来的,不是人写的。这篇来讲“涌现与训练——大模型是怎么学会的?”
什么是涌现?
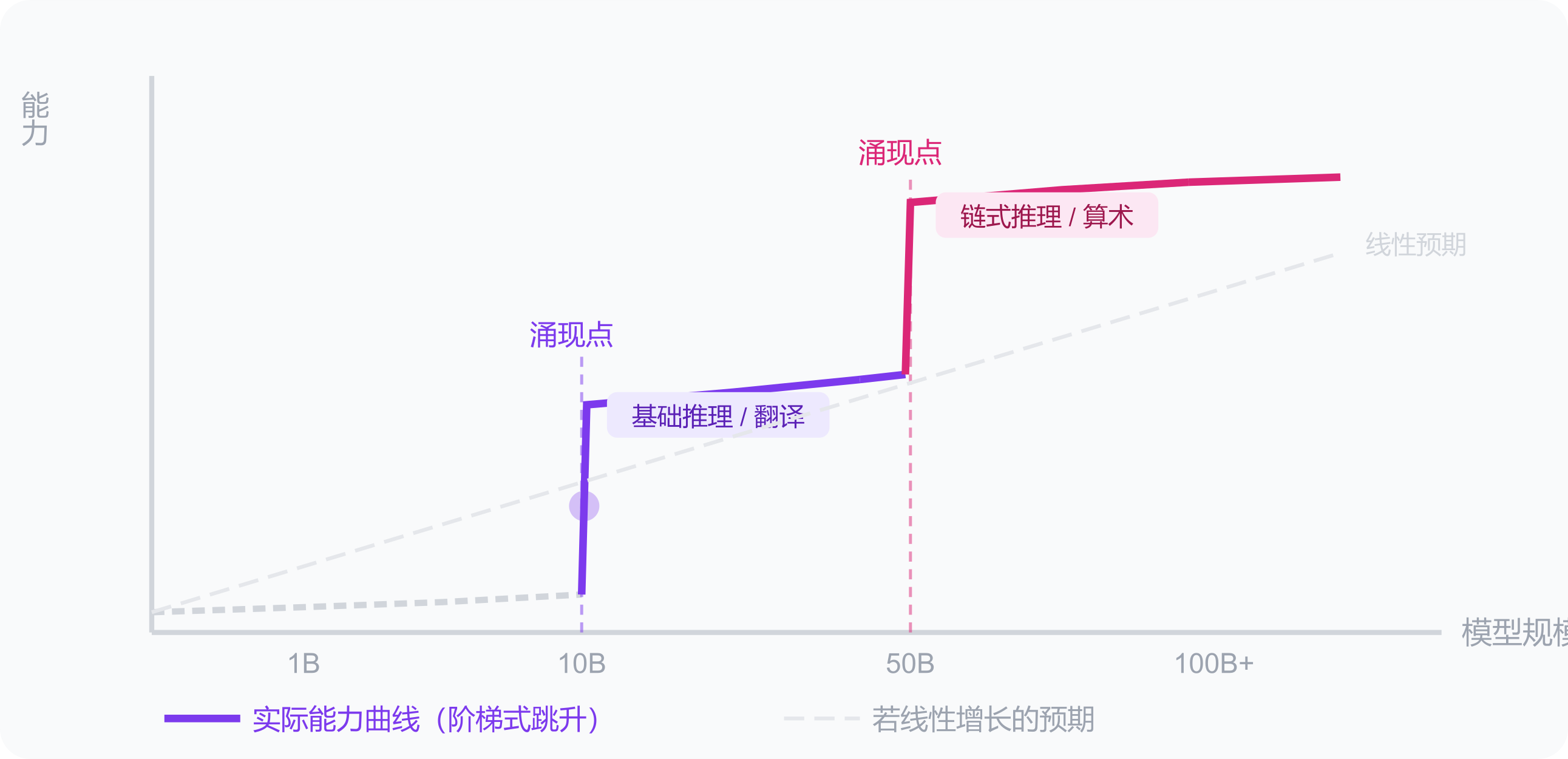
涌现(Emergence)= 小模型完全不会、大模型突然就会了的能力。
不是「随着规模增大慢慢变好」,而是在某个规模阈值前后,能力像开关一样跳变——之前表现接近随机,之后突然大幅跃升。
为什么不是线性增长?
模型参数翻倍,并不意味着能力翻倍。前期增加的参数在「打基础」——学词法、语法、常见搭配——这些积累在表面上看不出能力差异。当某个任务所需的所有子能力都达到临界点,能力才集中爆发出来。
类比:水降温到 0°C 之前,液态性质几乎没变化;跨过 0°C 瞬间结冰——相变就是涌现。
具体例子:
| 能力 | 小模型(≤10B) | 大模型(≥50B) |
|---|---|---|
| 基础翻译 | 勉强可用 | 流畅自然 |
| 数学应用题逐步推理 | 几乎不会 | 突然会了 |
| 少样本学习(看几个例子就推广) | 随机水平 | 明显有效 |
| 代码调试、解释错误 | 混乱 | 基本可靠 |
涌现让预测变难:你没办法只看小模型的表现来推断大模型会不会某个能力。这也是为什么每次发布更大模型,总会出现「惊喜」——那些能力在小模型阶段根本没有信号。
这和前面说的「非线性」是同一件事的不同层次:激活函数在神经元层引入非线性,让单个神经元能表达复杂判断;涌现是非线性在整个模型规模层面的体现,让能力随规模出现质变而非量变。
模型是怎么训练出来的?预训练是什么?
自监督学习:用海量文本,让模型不断预测「下一个词是什么」,预测错了就调整权重。
训练数据里有一句话:「今天天气很___」
模型猜:好 / 热 / 差
对比实际下一个词:好
错了 → 调整权重 → 再猜
不需要人工标注,文本本身就是答案。这叫自监督学习——数据提供了隐式反馈。
训练的完整循环:
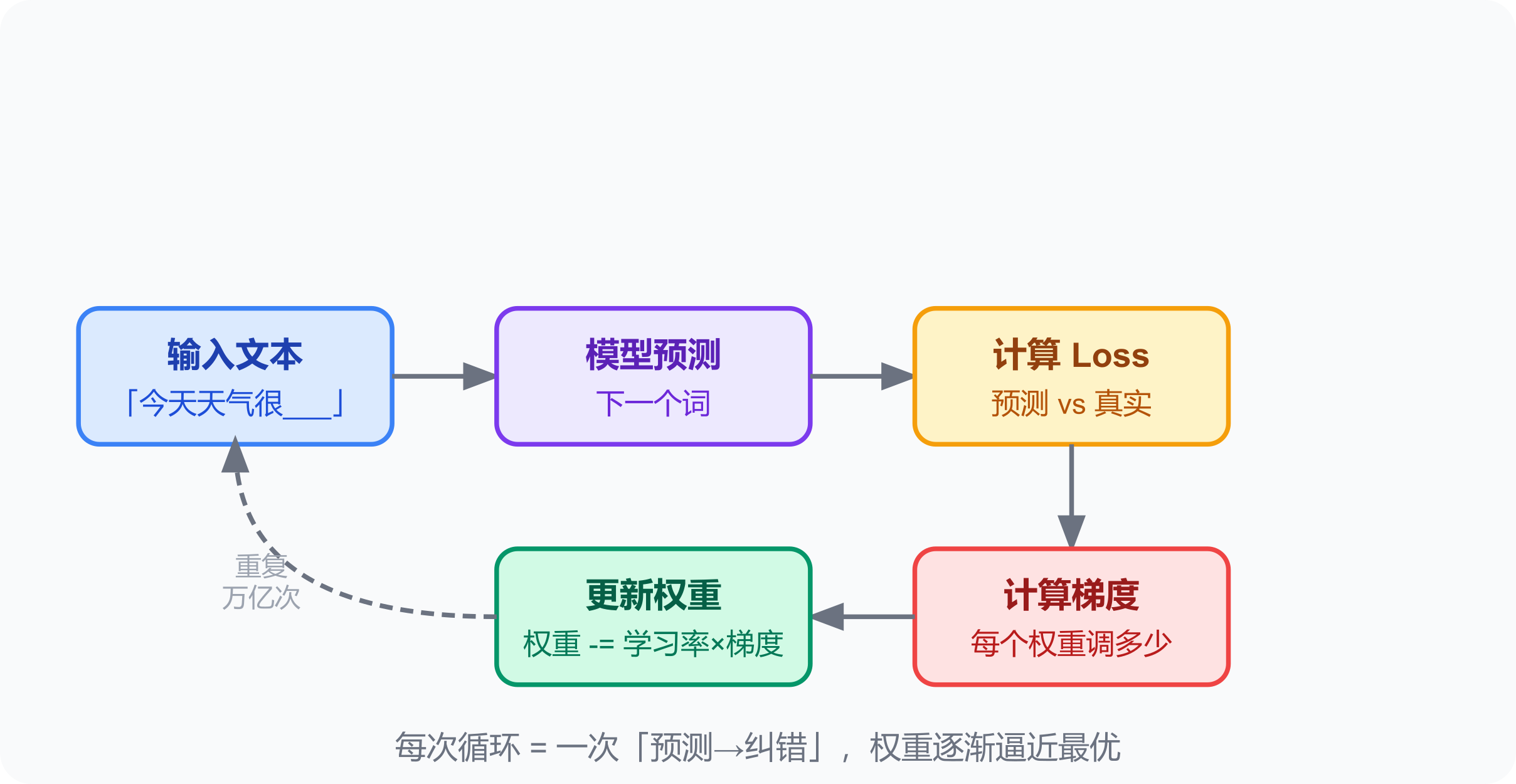
这个循环重复几万亿次,模型就「学会」了语言。
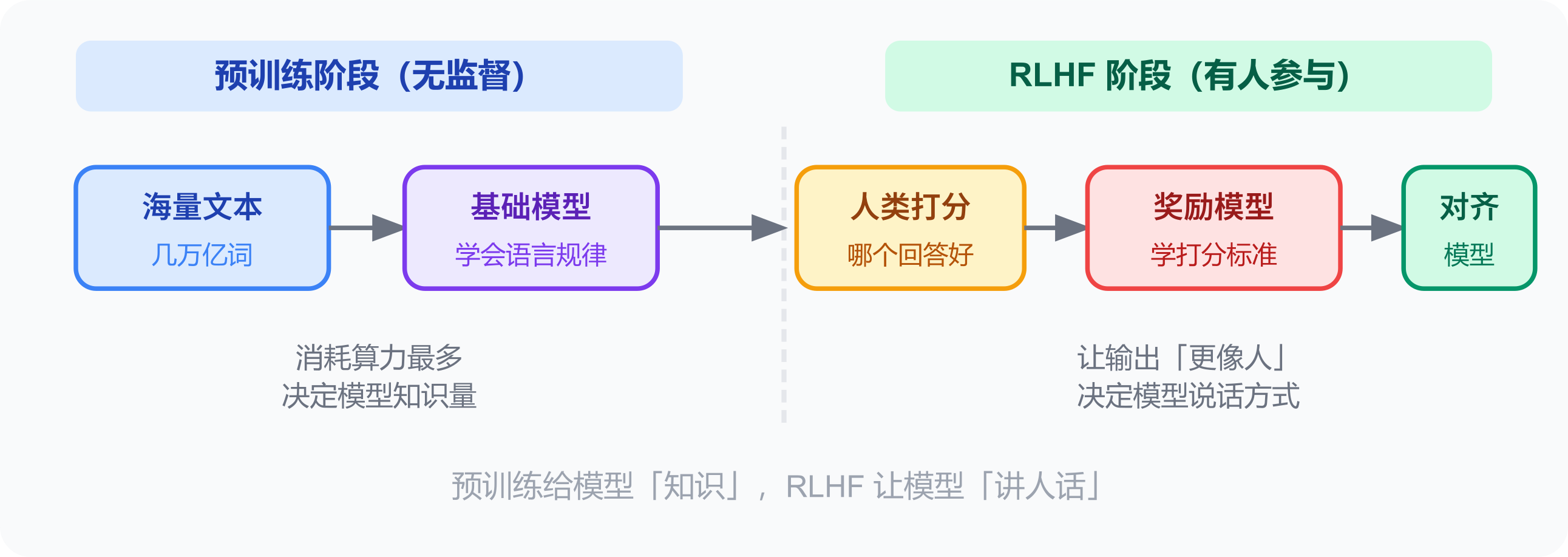
预训练:用几万亿个这样的填空,让模型学会语言规律。这是训练的主体阶段,消耗计算资源最多。
之后还有 RLHF(基于人类反馈的强化学习):人类对模型回答打分 → 训练奖励模型 → 让模型输出更符合人类偏好。这才是「有人打分评价」的阶段。
梯度是什么?谁给反馈?
梯度 = 每个权重「往哪个方向调、调多少」的指令。
可以用「下山」来直觉理解:
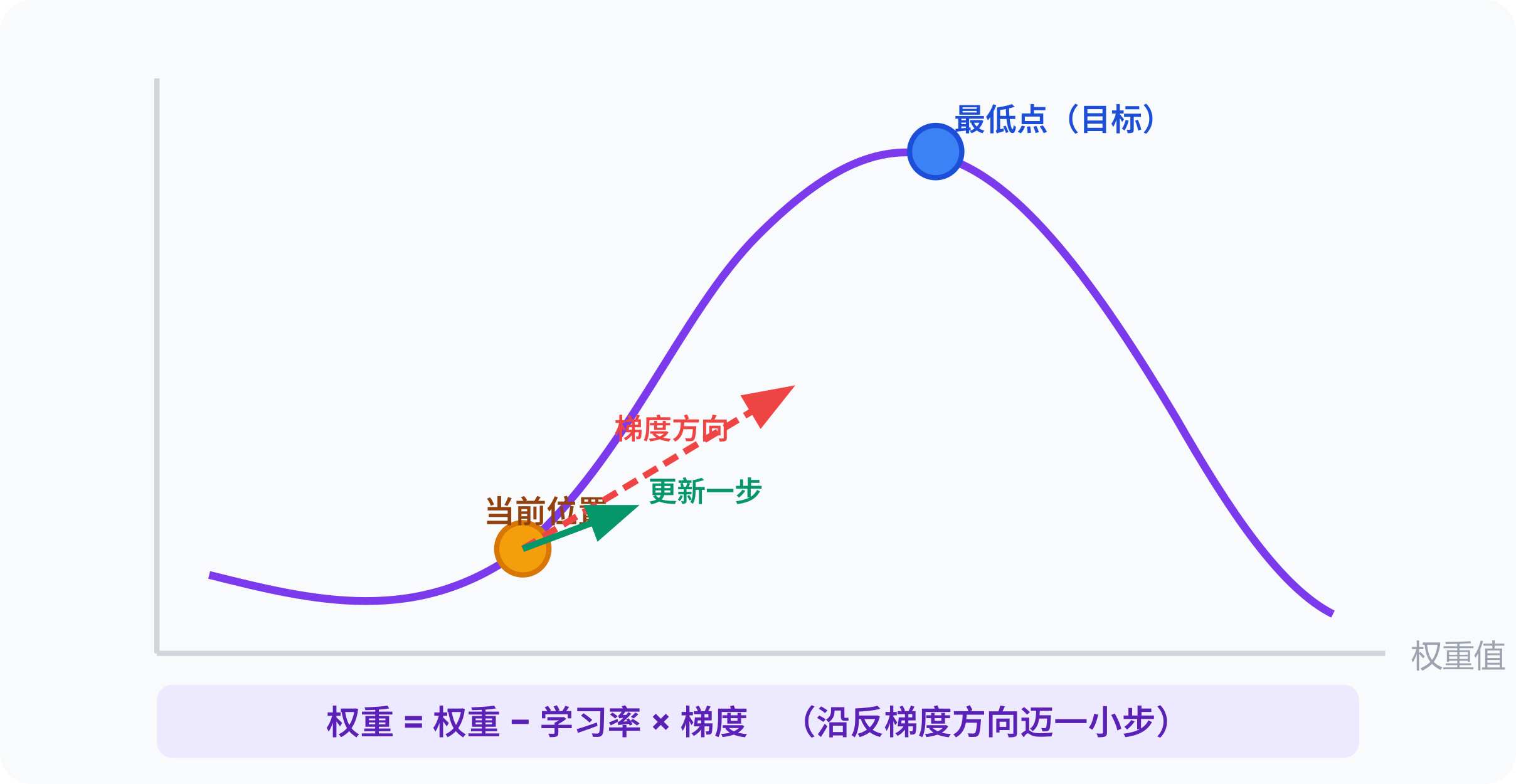
预测错了 → 计算 loss(错误程度)
对每个权重求偏导:「这个权重 +0.01,loss 变多少?」
这个导数 = 梯度
更新:权重 = 权重 - 学习率 × 梯度
梯度为负(权重增加则 loss 减少)→ 权重增加
梯度为正(权重增加则 loss 增加)→ 权重减少
谁给反馈:训练数据本身。预测「下一个词」,答案就在文本里,不需要人工标注。数据 = 隐式反馈源。RLHF 阶段才有人类显式打分。
训练不会等「loss 完全不减少」才停,而是固定跑多少步,或验证集 loss 开始上升就停(防止过拟合)。
什么是过拟合?「拟合」怎么理解?
拟合 = 让模型输出贴合数据。
过拟合 = 贴得太紧,把训练数据里的噪音和特例也学进去了 → 记住了答案,没有学到规律 → 遇到新数据失灵。
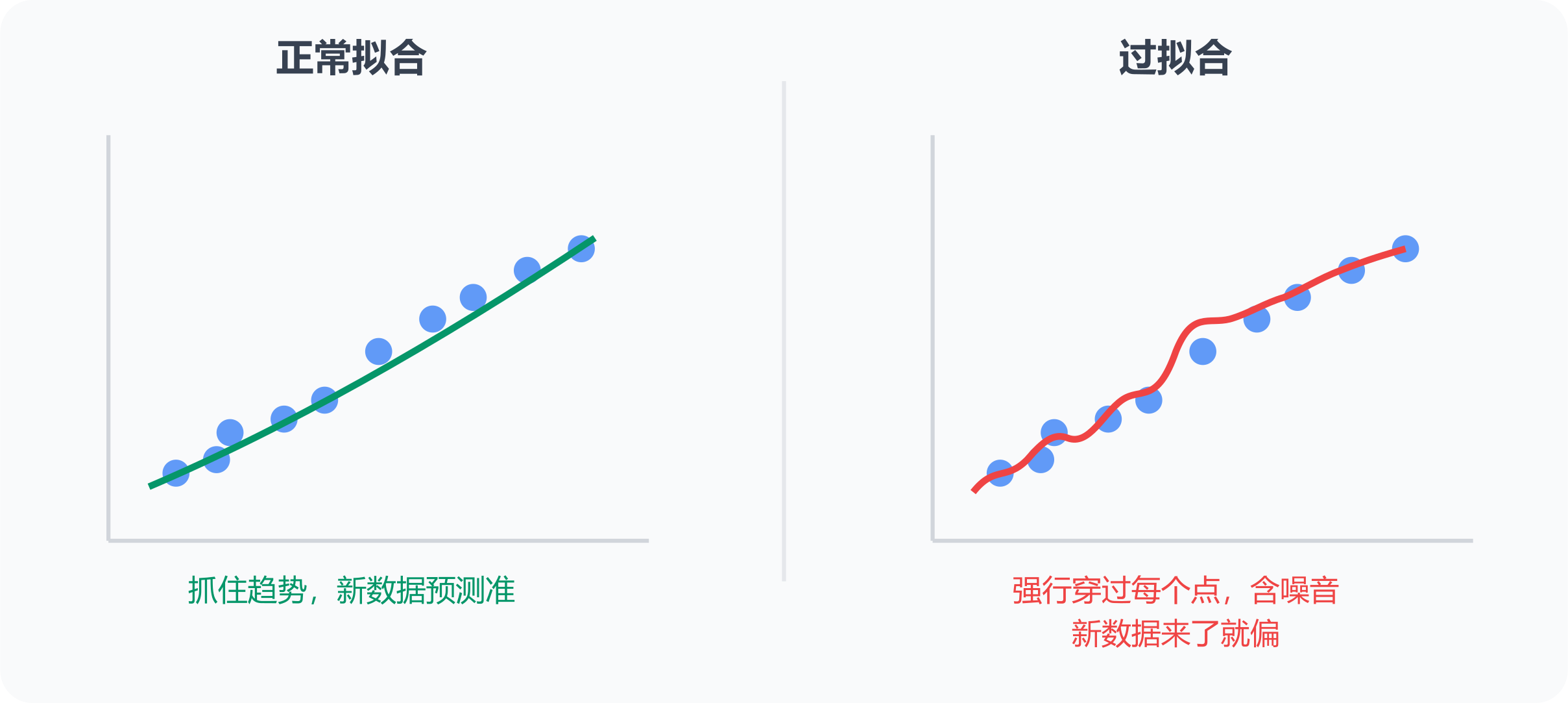
类比:学生死记硬背历年考题的答案,每道题都能背出来(训练 loss 极低),但换一道新题就不会了(验证 loss 很高)。
如何检测:
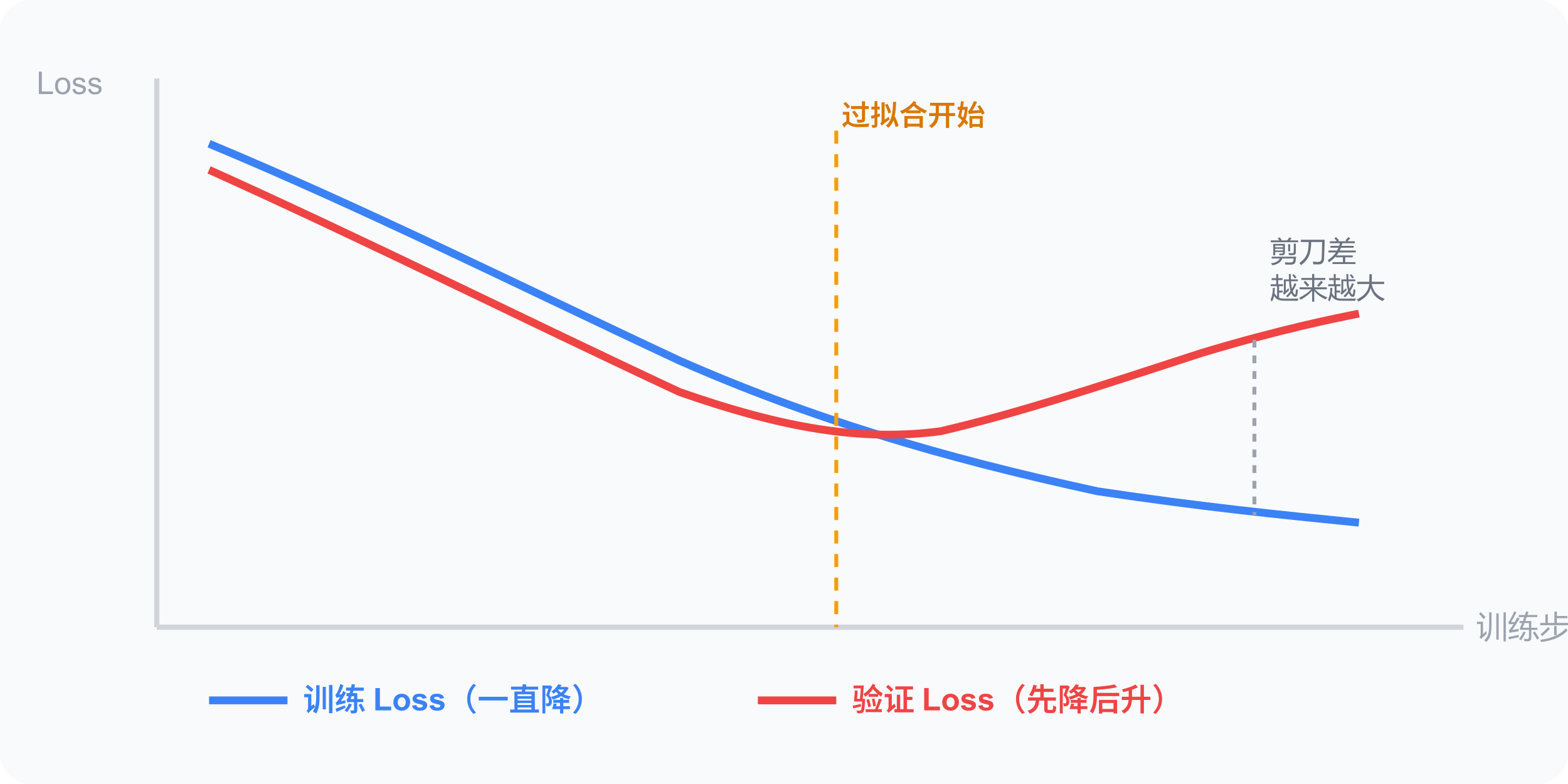
信号:训练 loss 持续降低,验证 loss 开始上升 → 剪刀差出现 → 过拟合了。过拟合是模型在训练集和新数据上表现出现分离。
本篇小结
这篇讲的是训练的完整过程——从涌现现象说起,到预训练的机制和梯度的直觉,再到过拟合的识别。把这些放在一起,是因为它们都在回答同一个问题:模型怎么从什么都不会,变成什么都能说?
- 自监督预训练:预测下一个词,文本本身就是答案,不需要人工标注;预训练消耗最多计算资源
- 梯度 = 调权重的指令:告诉每个权重往哪个方向调、调多少;用「下山找最低点」来直觉理解
- 过拟合 = 记住答案而非学到规律:训练 loss 低,验证 loss 高,剪刀差出现就是信号
理解了训练过程,才能理解为什么大模型「会说话」但不等于「知道事实」——这正是下篇要讲的核心问题。
延伸思考
学习就是不断犯错
大模型的训练,本质上就是反复试错。猜一个词,对比实际答案,算出错了多少,微调权重——这个循环重复了几万亿次。没有老师,没有规则,只有数据和反馈。人类学语言也是这样:听到的语言不断修正对「什么是正确表达」的感知,不需要先背语法规则。
量变与质变
涌现让很多人困惑:为什么把模型做大,能力会突然跳升?这不是「越来越好」的线性过程,更像水结冰——温度一直在降,但冰在某一刻突然出现。大模型也是这样:参数在积累,表面上看不出变化,但当某个任务所需的所有子能力都到位,能力就集中爆发。这也是为什么小模型的表现无法预测大模型——它们不是同一量级的延伸,而是不同的相态。
下一篇:幻觉 模型学会了语言,但它会说错——而且错得很自信。下篇解释幻觉的根本原因,为什么它不是「bug」而是能力本身的代价,以及有哪些现实可用的应对方法。