开一个新系列,整理我与 AI 的一些对话和思考,记录关于大模型、技术变化与智能时代的持续观察。技术部分是理解的基础,文末用日常语言做整体理解,是这篇的落点。
本文内容较长,分上、中、下三篇发布,此为上篇。可单独读,也可按顺序读。
目标读者:对 AI 好奇,想知道「它是什么,是怎么想的」。
这篇文章讲什么
大模型(LLM,Large Language Model) 是指像 ChatGPT、Claude、Geminii、DeepSeek、Kimi、豆包这类能理解和生成自然语言的 AI 系统。「大」指的是模型参数量巨大(通常数百亿个),「语言模型」指的是它的核心能力是理解和生成语言。
大模型不是在查数据库,也不是在执行人写好的规则——它是通过海量文本训练出来的「概率预测系统」,本质上在做一件事:预测下一个最可能出现的词。
这个机制带来了惊人的能力,也带来了一个著名的缺陷:幻觉(Hallucination)——模型会生成听起来很合理但实际上是错误的内容。理解幻觉的根源,是用好 AI 工具的基本功。
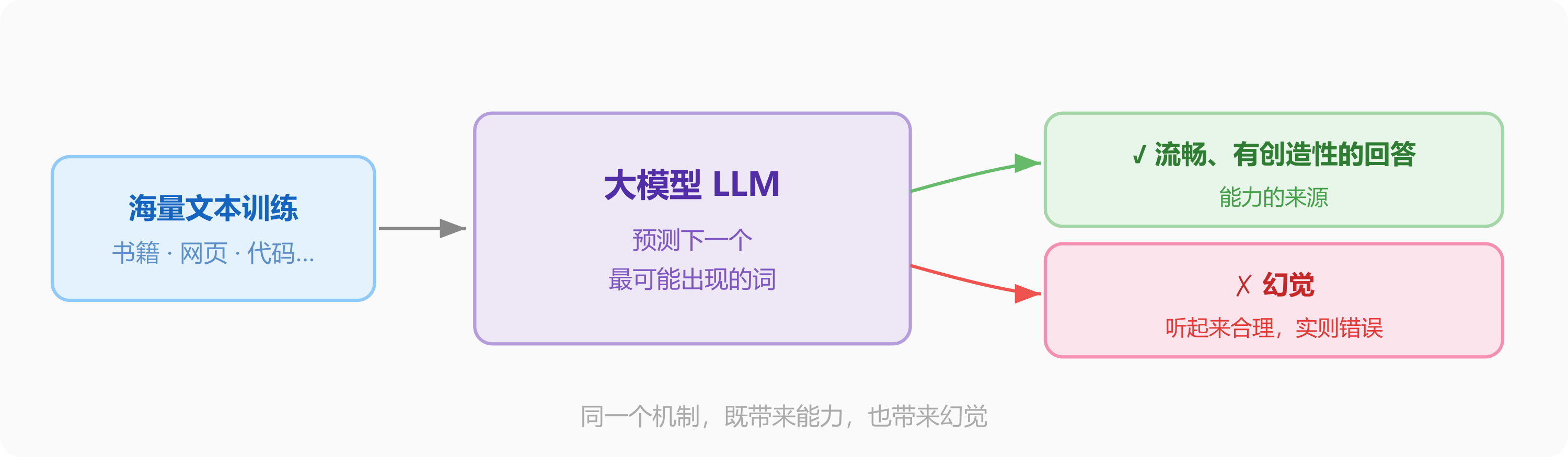
今天说的「AI」,大多数时候指的就是大模型。本篇从神经元、训练过程讲起,帮你建立对大模型工作方式的基本认知。
模型是用代码搭建的吗?它是把人类思维程序化了吗?
是。用代码搭建的,但内部的逻辑不是人写的,是学出来的。
代码定义了神经网络的结构(哪些「神经元」怎么连接),但权重(连接的强度)是通过训练自动调整的。没有人写「遇到这个问题用这个推理方法」,模型的「推理能力」是从海量数据里涌现出来的。
神经网络最原始的东西是什么?
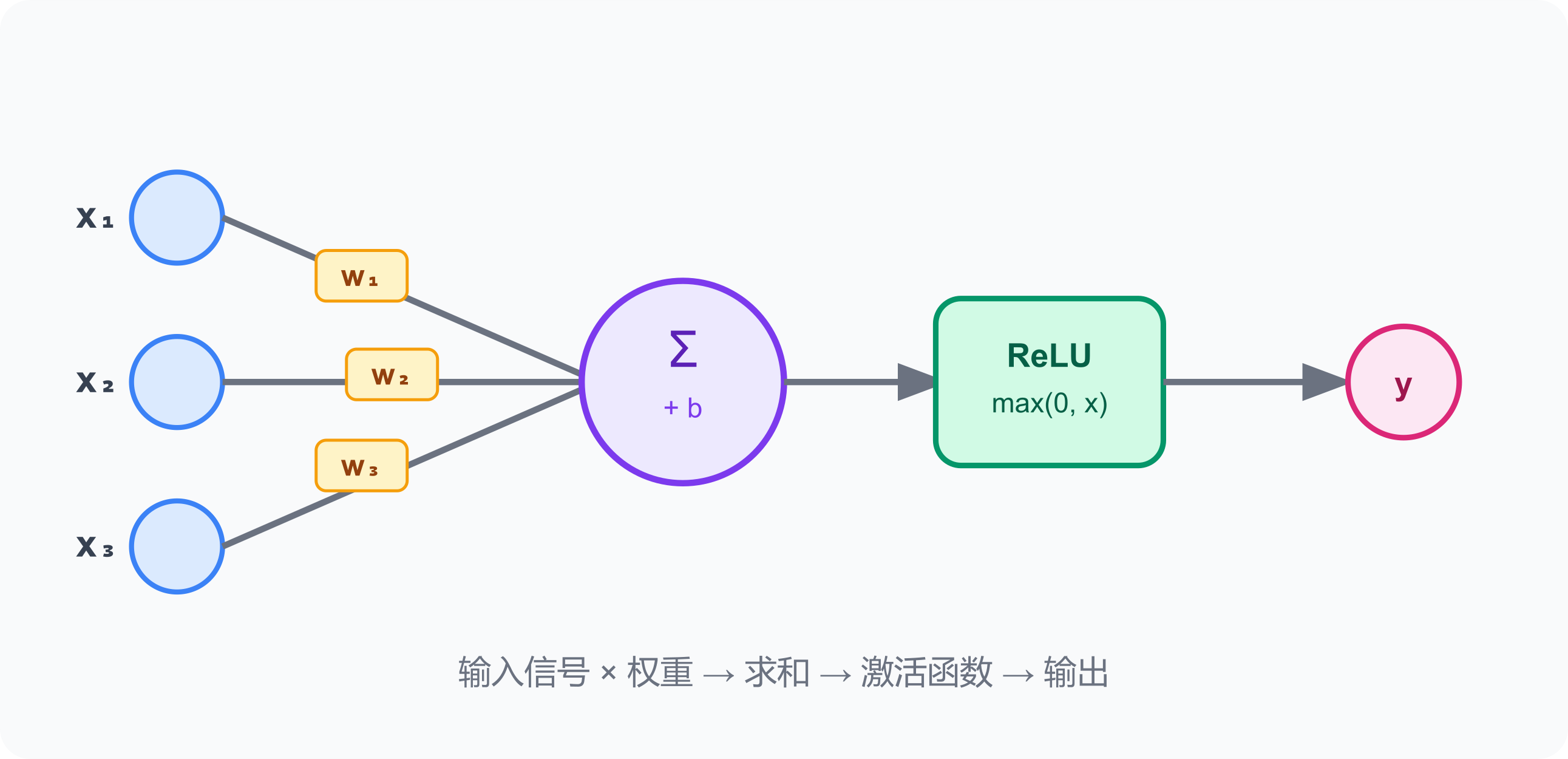
一个神经元:收多个输入(x1、x2、x3) → 每个乘以权重(w1、w2、w3) → 加在一起 → 经激活函数处理后输出。
输入 x1, x2, x3
加权求和:x1×w1 + x2×w2 + x3×w3 + b
激活函数:max(0, 结果) ← 引入非线性
输出一个数
可以画成这样:
成千上亿个这样的单元叠在一起 = 神经网络。结构(层数、连接方式)是人设计的,权重值是学出来的。
神经网络的「层」是什么概念?
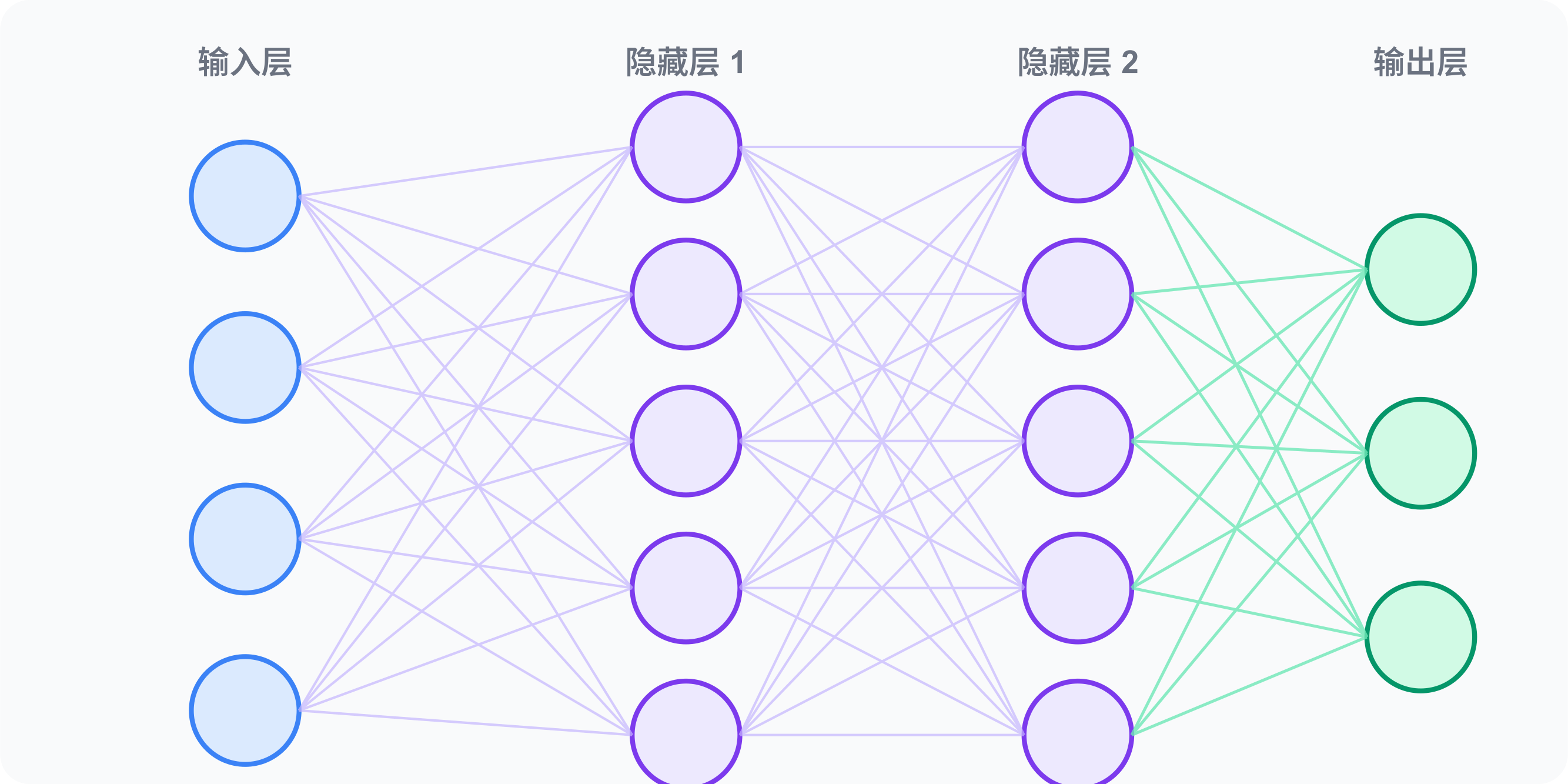
「深度」学习的「深」,就是指层数多——现代大模型有几十到上百层。
生物神经元也有权重:突触强度 = 反复激活的连接变强,不用的变弱(Hebb 规则,1949年神经科学家 Donald Hebb 发现)。人工神经网络用数字精确模拟了这个机制。
权重是不是就像肌肉记忆?或者「一人通过的小桥」和「十车道大路」?
对,这个比喻非常准确。
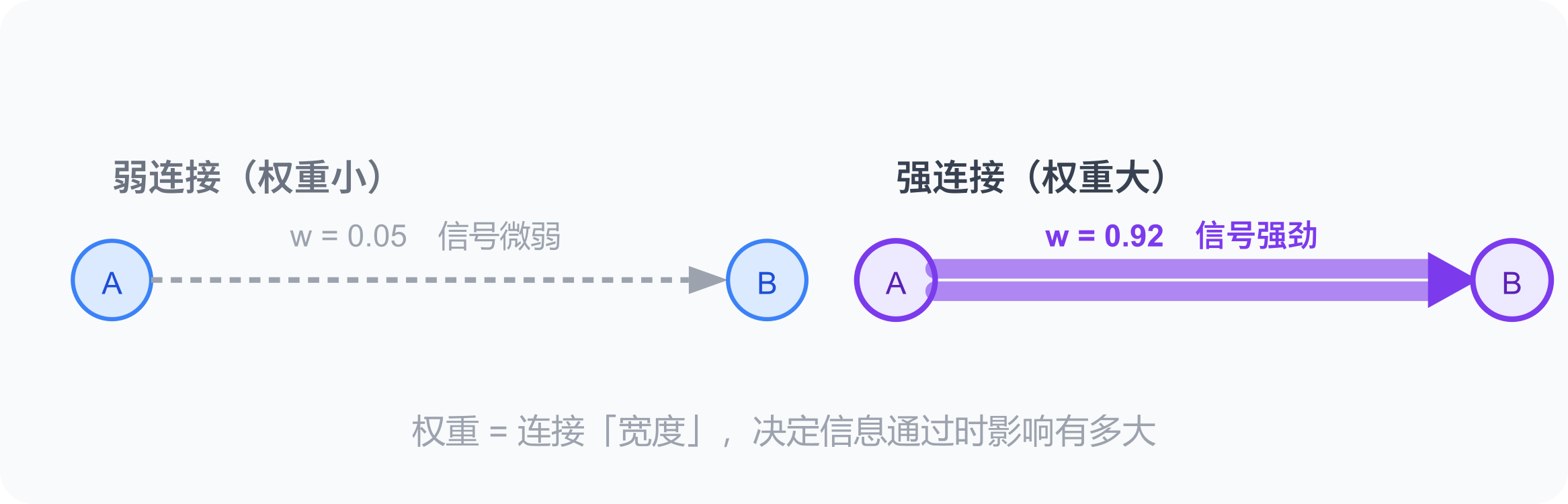
反复用某条路径 → 路变宽 → 通行更快更稳定。权重越大的连接,信息通过越顺畅,对结果影响越大。
肌肉记忆的神经机制也是这个:弹钢琴时反复练习的指法,对应的神经连接权重增加,不需要有意识控制就能流畅执行。
人工神经网络的训练权重,就是这个机制的数字版。
激活函数为什么要引入「非线性」?
线性叠多少层还是线性,解不了复杂问题。
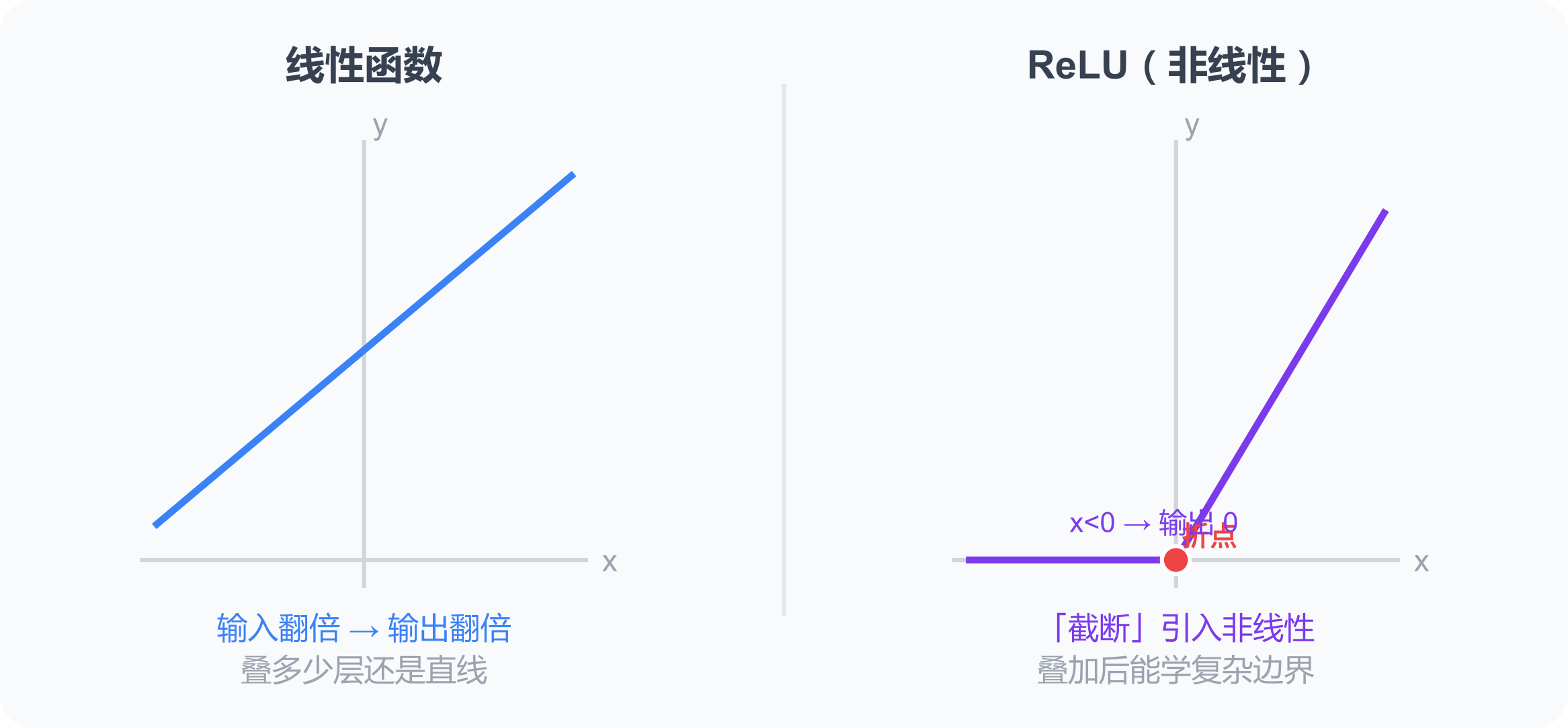
线性:输入翻倍 → 输出翻倍,可预测,只能表达直线关系。
激活函数(如 ReLU):输入小于 0 → 输出 0(截断);大于 0 → 正常输出。这个「截断」就是非线性。
多层叠加非线性 → 模型能学会「这个条件满足才激活,否则静默」——也就是分类、边界识别、复杂模式。
「突破到某个层级后,回报成倍增长」——这也是非线性的一种体现:AI 能力随规模增大出现「涌现」现象,某个阈值后能力突然跳升,不是线性增长。
本篇小结
大模型不是人工写规则的系统——它的「智能」来自结构加数据,逻辑是训练出来的,不是编程进去的。本篇建立的是最底层的认知:
- 神经元 = 加权求和 + 激活函数:权重决定连接强度,激活函数引入非线性,让模型能学复杂模式
- 权重是训练出来的:代码定义结构,权重值通过梯度下降自动调整,没有人手写规则
- 非线性的意义:线性叠多少层还是线性;非线性让「涌现」成为可能——能力随规模超线性增长
- 内部的逻辑是学出来的:模型的「推理能力」是从海量数据里涌现出来的
延伸思考
简单单元,复杂行为
神经网络的反直觉之处在于:每个最小单元极其简单,只会做加法和乘法;但几十亿个这样的单元叠在一起,配上足够多的数据,就能涌现出读懂语言、理解意图的能力。这不是设计出来的,是学出来的。
类似蚁群:单只蚂蚁没有智能,但整个蚁群能解决复杂问题。大模型的「聪明」不在任何一个神经元里,而在亿万个连接的整体涌现中。
权重就是反应
如果要找一个最贴近「大模型学了什么」的比喻,权重是最准确的答案。它不是存了哪些知识,而是形成了一套反应模式——遇到这种输入,倾向于产生那种输出。就像一个人经历了很多事情之后,形成了自己的直觉和判断方式。这些判断不是规则,是习惯。
下一篇:涌现与训练 积木搭好之后,模型怎么「学会」东西的?为什么小模型和大模型之间存在能力的质变而非量变?训练循环是怎么运转的,梯度和过拟合又意味着什么——中篇展开这些问题。