记录解决问题的过程
关键词:B 站,Bili,弹幕,Aria2,libz::inflate() failed,incorrect header check,Node,Zlib,Transfer-Encoding,chunked,Content-Encoding,gzip,deflate,zlib,raw
7 月 13 日
遇到错误
在完善 B 站视频下载 时,下载弹幕文件出现了问题。
错误:libz::inflate() failed. cause:incorrect header check
相关报错图和文字版:
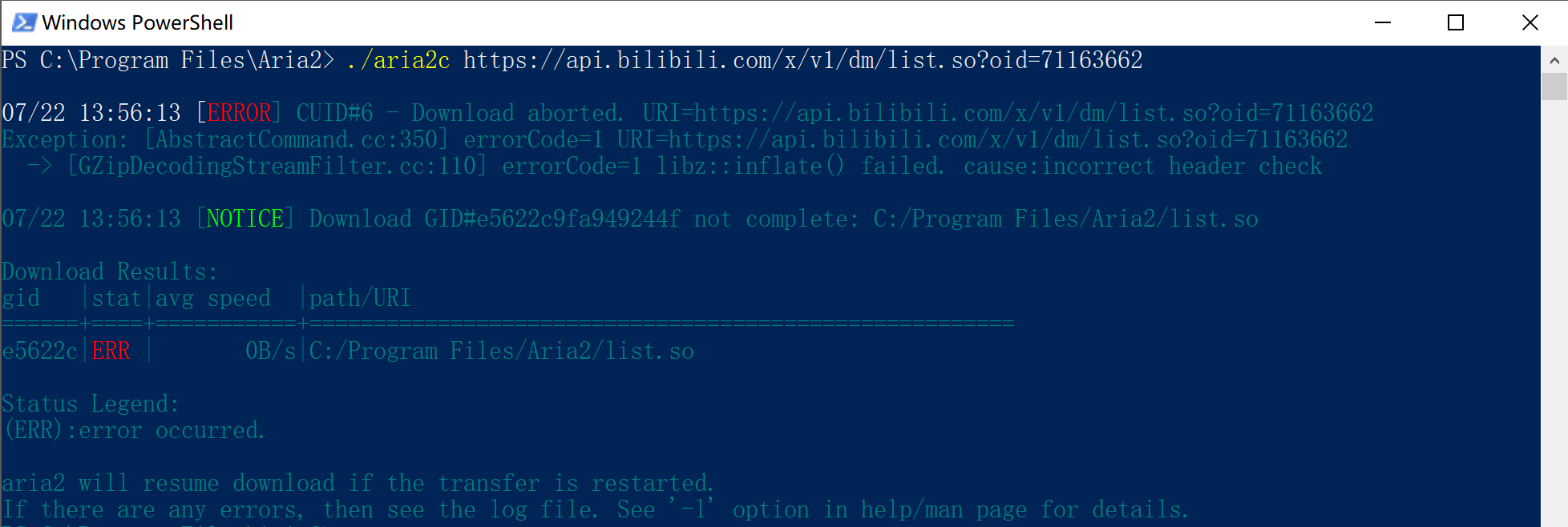
PS C:\Program Files\Aria2> ./aria2c https://api.bilibili.com/x/v1/dm/list.so?oid=71163662
07/22 13:56:13 [ERROR] CUID#6 - Download aborted. URI=<uri>
Exception: [AbstractCommand.cc:350] errorCode=1 URI=<uri>
-> [GZipDecodingStreamFilter.cc:110] errorCode=1 libz::inflate() failed. cause:incorrect header check
...
提交 issues
查看 Aria2 官方文档后,添加了--http-accept-gzip ,依旧如初,提交了 issues 。
7 月 14 日
初遇 Transfer-Encoding
从报错的信息中可以看到 incorrect header ,文件头部信息有误。
于是我再次查看了报文:
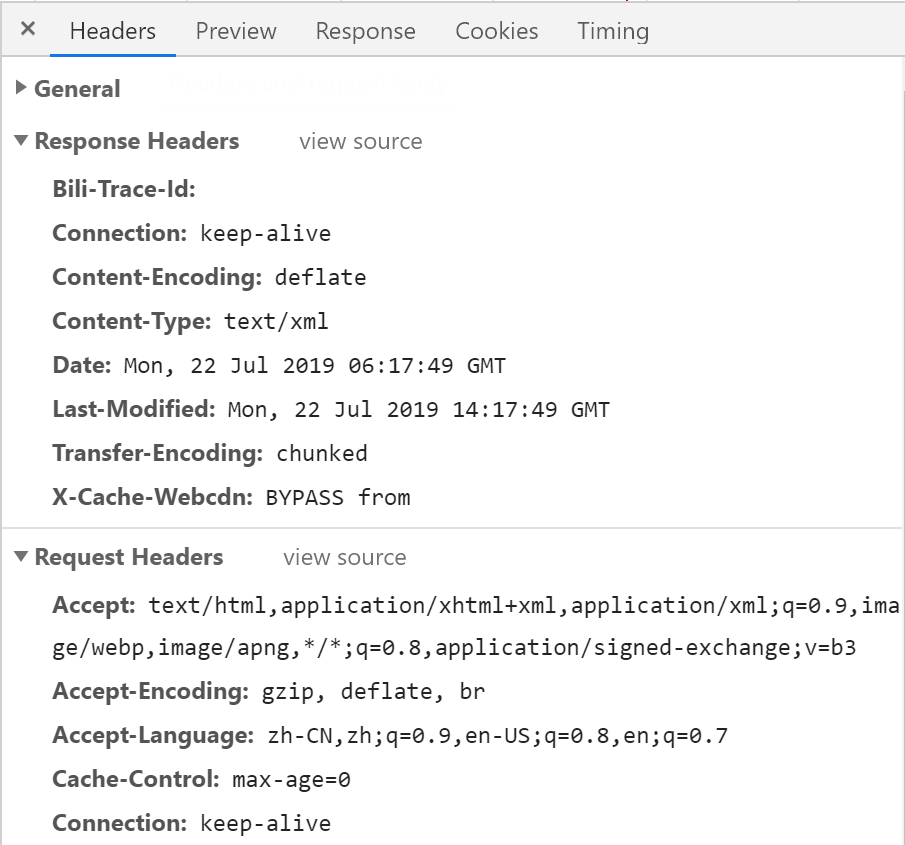
其中比较关键的两点:
① Content-Encoding: deflate:内容编码,通常用于对实体内容进行压缩编码。
② Transfer-Encoding: chunked: 传输编码,数据以一系列分块的形式进行发送。
一个 HTTP 报文基本同时使用这两种编码,针对进行了内容编码(压缩)的内容再进行传输编码(分块)。
推荐文章:HTTP 协议中的 Transfer-Encoding、Transfer-Encoding: gzip vs. Content-Encoding: gzip
curl
经过几个工具的测试,curl 成功获得了 XML 文件,目前唯一成功的方法
curl -O url --compressed
而使用 Node.js 测试失败:
实际上并不是 Node.js 的问题,而是此时我对 Zlib 的理解问题。同时不知怎么迷糊了,明明是 deflate ,却用的是 gzip。
fs.createReadStream('./1.gz').pipe(zlib.createGunzip()).pipe(fs.createWriteStream('1.xml'))
7 月 15 日
下载工具有误
想着"关门造车"也不对,于是发了咨询贴:疑问:请问如何解压 B 站弹幕文件?
最终结论是,Aria2 的工具自身有误。
发帖时怀疑是解压问题,之后怀疑是 Aria2 不支持 chunked(错误,先压缩再分块,已有文件,分块已合并,chunked 结束),最后确实是解压方式的问题。
一直尝试的 gzip 方式,以及贴中一直说 gzip 的原因,应该是昨天看了 Aira2 的源码,但是发帖后混淆了。
之后时间去写个人网站代码了...
7 月 21 日
规划工具的架构,弹幕模块到底要怎么易用。
自行搭建局域网服务,作为中间件,返回目前 Aria2 版本支持的格式,下载弹幕时请求此 API ,这样就能与下载封面图功能保证相似性。
本身问题的核心,就在于弹幕接口返回的数据。
Aria2 支持 chunked && deflate
有趣的是,在搭建的过程中,发现 HTTP Server 首部竟然有 Transfer-Encoding: chunked !
赶忙测试了 Arai2,res.writeHead(200, { 'Content-Encoding': 'deflate' }) ,甚至加不加 --http-accpet-gzip 都是成功的!
zlib.deflate("<p style='color:red'>Hello world!</p>", (err, buffer) => {
res.writeHead(200, { 'Content-Encoding': 'deflate' })
res.end(buffer)
}
说明错误并不是因为 Arai2 不支持 Transfer-Encoding: chunked,也不是不能解压 deflate 。
InflateRaw
此刻请求弹幕 API 依旧是辣个错误,我非常怀疑是服务器返回的数据有问题。测试以下输出:
response.pipe(zlib.createBrotliDecompress()).pipe(output); // error
response.pipe(zlib.createGunzip()).pipe(output); // error
response.pipe(zlib.createInflate()).pipe(output); // error
response.pipe(output); // 未解压文件
经过仔细翻阅 Node.js 文档,我突然发现了 zlib.createInflateRaw() 方法,请注意多了一个 Raw !
const zlib = require('zlib'), https = require('https'), fs = require('fs')
const request = https.get('https://api.bilibili.com/x/v1/dm/list.so?oid=71163662')
request.on('response', (response) => {
const output = fs.createWriteStream('1.xml')
response.pipe(zlib.createInflateRaw()).pipe(output)
})
成功了~!!!
翻阅文档,有无 Raw 的区别,就是无有 zlib header 的区别。
Class: zlib.DeflateRaw
Compress data using deflate, and do not append a zlib header.
7 月 22 日
查看源码
在 Github 查看了 Arai2、Node.js Zlib 、Zlib 相关源码,以及 Stackoverflow 相关问题。

aria2/src/GZipDecodingStreamFilter.h:

可见 Aria2 是直接指定以 gzip 的方式解压 deflate 的,但问题是 deflateInit2 这个函数的第四个参数 windowBits 代表的压缩方式:
-15~-8: raw deflate
8~15: 带 zlib 头和尾的 deflate
>15: 带 gzip 头和尾的 deflate
其中的 raw deflate 的情况报错了。
破案了
最终原因是,B 站返回的数据是 raw deflate,而 Aria2 支持的是带 zlib 头尾的 deflate 。
最后
针对 B 站弹幕数据,它首先对数据进行了压缩(Content-Encoding: deflate)再进行分块(Transfer-Encoding: chunked),以下代码来验证,其中 list.so 是下载后未解压的文件,list.xml 是采用正确解压方法后的文件:
const zlib = require('zlib')
, fs = require('fs')
const input = fs.createReadStream('list.so')
, output = fs.createWriteStream('list.xml')
input.pipe(zlib.createInflateRaw()).pipe(output)
而 B 站的弹幕压缩数据格式并不正确,它并没有被 zlib 包装,raw deflate 是微软的错误,建议改用 gzip。
推荐两篇文章,来龙去脉讲的很详细:HTTP 协议中的 Content-Encoding,deflate——过时的网页压缩格式,最好禁用[转] ,我就不多言了。